JDBC-封装
基本上所有在学习jdbc的时候,都做过简单的封装,jdbc的基本流程如下
- 定义数据库连接参数
- 打开数据库连接
- 声明SQL语句
- 预编译并执行SQL语句
- 遍历查询结果(如果需要的话)
- 处理每一次遍历操作
- 处理抛出的任何异常
- 处理事务
- 关闭数据库连接
其中第一和第二步已经由我们的数据源管理处理了。但是接下来的N步,每次都要写也是繁琐的。于是首先我们可以把好抽象的部分拿出来。代码如下:
public static int execute(String sql, Object... params) {
Connection connection = null;
PreparedStatement ps = null;
try {
connection = getConnection();
ps = connection.prepareStatement(sql);
fillStatement(ps, params);
return ps.executeUpdate();
} catch (Exception e) {
logger.error("execute sql error ! sql:{} params:{}", sql, params, e);
throw new DBException(e);
} finally {
dispose(null, ps, connection);
}
}可以看到,我们这个方法需要传入sql和参数,之后获取PreparedStatement,参数的设置使用占位符的方式,这里有一个技巧就是在setParam的时候全部使用setObject方法,这样可以避免掉类型的转换处理,fillStatement代码如下:
public static void fillStatement(PreparedStatement stmt, Object... params)
throws SQLException {
if (params == null) {
return;
}
ParameterMetaData pmd = null;
if (!pmdKnownBroken) {
try {
pmd = stmt.getParameterMetaData();
if (pmd.getParameterCount() < params.length) {
throw new SQLException("Too many parameters: expected "
+ pmd.getParameterCount() + ", was given "
+ params.length);
}
} catch (Exception e) {
pmdKnownBroken = true;
}
}
for (int i = 0; i < params.length; i++) {
if (params[i] != null) {
try {
stmt.setObject(i + 1, params[i]);
} catch (Exception e) {
// 处理oracle的日期类型,如果java.util.Date设置失败,使用java.sql.Timestamp
if (params[i] instanceof java.util.Date) {
Timestamp date = new Timestamp(
((java.util.Date) params[i]).getTime());
stmt.setObject(i + 1, date);
}
}
} else {
// VARCHAR works with many drivers regardless
// of the actual column type. Oddly, NULL and
// OTHER don't work with Oracle's drivers.
int sqlType = Types.VARCHAR;
if (!pmdKnownBroken) {
try {
sqlType = pmd.getParameterType(i + 1);
} catch (SQLException e) {
pmdKnownBroken = true;
}
}
stmt.setNull(i + 1, sqlType);
}
}
}在注释部分处理了Oracle数据库的日期设置,避免了set失败的问题 这样一个执行sql的方法就可以用了,用这个方法可以执行update,delete但是insert方法可能由一点差别,具体见:JDBC-方言,但是最复杂多变的在于select,返回多种多样的数据,需要我们处理成不同的格式。JDBC执行完查询时候,都会返回一个ResultSet,对于rs的处理, 可以分为几类
1.返回单表对象:一个或者多 2.count等函数查询,返回数值或者单个字段的 3.返回多个表关联对象:一个或者多个
我们需要针对不同的返回结果进行处理,这里要提到一个轻量级的工具DBUtils,仅仅几十个类,完成了这些抽象,设计的非常巧妙,上面的fillStatement方法就是从DBUtils中借鉴的 针对不同的返回结果,DBUtils定义了一个接口ResultSetHandler,如下:
public interface ResultSetHandler<T> {
/**
* Turn the <code>ResultSet</code> into an Object.
*
* @param rs The <code>ResultSet</code> to handle. It has not been touched
* before being passed to this method.
*
* @return An Object initialized with <code>ResultSet</code> data. It is
* legal for implementations to return <code>null</code> if the
* <code>ResultSet</code> contained 0 rows.
*
* @throws SQLException if a database access error occurs
*/
T handle(ResultSet rs) throws SQLException;
}这个接口只有一个方法,就是处理rs,返回的结果是一个泛型的结果,然后又定义了各种的抽象类及具体的实现,如
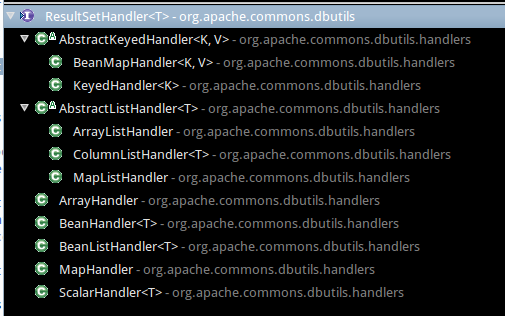 在接口下提供了很多的实现,包括了我们上面提到的所有返回结果的处理,在使用的时候只要使用对应的处理实现即可。这里不再赘述,具体请自行查看
在接口下提供了很多的实现,包括了我们上面提到的所有返回结果的处理,在使用的时候只要使用对应的处理实现即可。这里不再赘述,具体请自行查看
dbutils的使用。使用了DBUtils之后,我们的封装变成了如下结果:
public static <T> List<T> query(Class<T> beanClass, String sql,
Object... params) {
Connection conn = getConnection();
try {
return queryRunner.query(conn, sql,
Reflect.isPrimitive(beanClass) ? new ColumnListHandler<T>()
: new BeanListHandler<T>(beanClass,
new CustomRowProcessor(
new StrategyBeanProcessor(
new HumpMatcher()))),
params);
} catch (SQLException e) {
logger.error("Query list error !", e);
throw new DBException(e);
} finally {
freeConnection(conn);
}
}query方法只需要传入特定的class,sql和参数,即可把返回结果处理为class对应的对象,在也不用编写繁琐的rs.getxxx, bean.setxxx。实现原理就是通过获取传入class的类描述及字段描述等信息,然后调用具体的set方法给字段赋值返回即可,相应的返回map等实现都大同小异。
如果你想使用jdbc,使用dbutils再加上自己的一点封装即可, 如果你还在使用jdbc最原始的方式,好吧,你再浪费你的生命。。。